

The term Artificial Intelligence was first used by John McCarthy in a small gathering of scientists in 1956 at Dartmouth College in New Hampshire. Claude Shannon, the father of information theory, and Herb Simon, the only person ever to win both the Nobel Memorial Prize in Economic and Turing Award in computer science also participated in it.
At the 1956 conference, there were already several approaches to the topic. Historians believe that one of the reasons McCarthy coined the name artificial intelligence, or AI, for his research was because it was broad enough to embrace them all, leaving open the question of which was best. Some researchers preferred systems that combined facts about the world with axioms from geometry and symbolic logic to infer appropriate responses; others preferred systems in which the probability of one thing was determined by the constantly updated probabilities of many others.
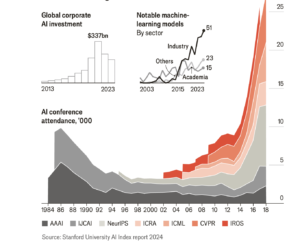
The ensuing decades witnessed great intellectual ferment and debate on the subject, but by the 1980s, there was broad consensus on the path forward: “expert systems” that employed symbolic logic to capture and apply the best of human know-how. The Japanese government, in particular, has thrown its weight behind the concept of such systems and the gear they may require. But, for the most part, such systems proved too rigid to deal with the complexities of real life. By the late 1980s, artificial intelligence had become synonymous with overpromising and under delivering. Researchers who were still working in the field began to avoid using the word. For twenty years, from 1990 to 2010, AI entered a silent period and the interest, even among scientists, as you can see in this chart, diminished.
The early attempts in developing AI Models in the 1970s and 1980s were not satisfying. But these attempts created the cushions for the current success and reputation. As the fundamentals of how brain cells—a sort of neuron—worked were uncovered in the 1940s, computer scientists began to explore if machines could be modeled similarly. In a biological brain, neurons are connected in such a way that activity in one can either activate or suppress activity in another; what one neuron does is determined by what the other neurons connected to it do. Marvin Minsky, a Dartmouth student, made the first attempt to mimic this in the lab by using hardware to model neural networks. Since then, layers of interconnected neurons have been simulated using software.
These artificial neural networks are not built with explicit rules; rather, they “learn” through exposure to a large number of examples. During this training, the strength of the connections between neurons (known as “weights”) is constantly modified until a given input gives an adequate output. Minsky abandoned the project, but others carried it forward. By the early 1990s, neural networks had been trained to perform tasks such as sorting mail by recognizing handwritten numerals. Researchers hypothesized that adding more layers of neurons would enable more advanced achievements. But it also caused the systems to run substantially slower.
The computation speed problem was solved at a dormitory in Stanford University in 2009. Stanford University researchers enhanced the speed of a neural network by 70 times. This was feasible because, in addition to the “central processing unit” (cpu) included in all computers, this personal gaming computer included a “graphics processing unit” (gpu) for creating game worlds on screen. And the GPU was built to run neural network programming.
Combining the hardware acceleration with more effective training techniques allowed networks with millions of connections to be trained in a reasonable amount of time; neural networks could accept larger inputs and, most importantly, be given more layers. These “deeper” networks proved to be far more capable.
The ImageNet Challenge of 2012 demonstrated the power of this new approach, which has become known as “deep learning”. Image-recognition algorithms competing in the competition were given access to a database of over a million annotated image files. The database contains several hundred pictures for each particular word, such as “dog” or “cat”. Using these examples, image-recognition algorithms would be trained to “map” input (pictures) onto output (one-word descriptions). When presented with previously unseen test images, the systems were challenged to create such descriptions. In 2012, a team led by Geoff Hinton, while at the University of Toronto, employed deep learning to attain 85% accuracy. This was considered as a breakthrough point in the history of AI. Eventually an accuracy rate of 96 percent was achieved, which made the AI models more accurate than human beings in this regard.
The next significant step forward in AI development occurred in 2017, when a novel method of organizing connections between neurons known as the transformer was introduced. Transformers allow neural networks to retain track of patterns in their input, even if the elements are widely apart, allowing them to provide “attention” to certain aspects in the data. Transformers improved networks’ understanding of context, making them suitable for an approach known as “self-supervised learning”. In essence, some words are randomly blanked out during training, and the model learns to fill in the most plausible choice. Because the training data does not need to be labeled beforehand, such models can be trained with billions of words of raw text downloaded from the internet.
Transformer-based large language models (LLMs) gained traction in 2019 when OpenAI, a startup, released a model known as GPT-2. Such LLMs proved to be capable of “emergent” behavior for which they had not been explicitly trained. Soaking up massive volumes of English made them not just remarkably adept at linguistic tasks like summarization or translation, but also at things inherent in the training data, such as simple mathematics and software creation. Less fortunately, it also meant that they reproduced biases in the data supplied to them, resulting in the emergence of many of human society’s entrenched preconceptions.
In November 2022, a larger OpenAI model, GPT-3.5, was introduced to the public as a chatbot. Anyone with a web browser could type a prompt and receive a response. No consumer product has ever taken off so quickly. Within weeks, ChatGPT was producing everything from undergraduate essays to computer code. AI had made another significant step forward.
Source: Economist



